
 --2022.4.10
--2022.4.10
Prerequisites
AVL 树
Definition
Adelson-Velsky & Landis树,也叫平衡二叉树,简略的说就是BST和高度平衡的二叉树的融合
BST,二叉搜索树,可以看作是以树结构存储的升序数组高度平衡的二叉树,任意节点的左右子树高度差
<=1,比如这棵就是

AVL的递归定义为:
- 是
BST,且左右子树高度差的绝对值<=1 - 子树也是
AVL
balance factor:平衡因子,因为AVL是高度平衡的,所以需要一个指标判断是否平衡,在失衡后触发平衡操作
BL=abs(h(n->left)-h(n->right)),即左右子树的高度差基于平衡因子,
AVL的第二条定义可以为:任意节点的平衡因子的绝对值<=1树的高度定义:
从根节点到叶子节点的路径包含的节点数的最大值(包括根节点)
leetcode,虽然求得是最大深度,不过深度和高度其实差不多
后序遍历:
先序遍历:


插入和删除节点之后,要更新高度,要更新高度的节点为操作节点的所有祖先节点
平衡
平衡是自底而上的,即从离操作节点最近的失衡的祖先节点开始,平衡有两种操作,左旋和右旋
右旋:
c.balanceFactor > 1
C节点及其子节点都是>=B 的,所以可以接到 B 的右子树,如果节点 B 有右子树,通常的策略是先断开 B 的右子树,将 C 接到 B 的右边,然后把右子树接到 C 的左边
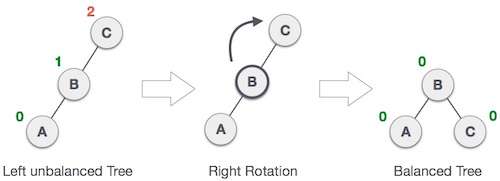
同理,左旋和右旋基本是对称的操作
旋转操作会改变树的结构,方便起见,节点的结构中parent为指向父节点的指针
左旋示例:
typedef struct Node {
Node* left;
Node* right;
Node* parent;
int val;
int height;
int factor;
}node,*nptr;
node* LeftRotate(node* cur) { //左旋cur
if (!cur) return;
if (cur->parent) {
node* n =
(cur->parent->left == cur) ? cur->parent->left : cur->parent->right;
n = cur->right;
cur->right->parent = cur->parent;
}
node* cr = cur->right;
node* crl = cr->left;
if (crl) crl->parent = cur;
cur->right = crl;
cr->left = cur;
return cur->parent = cr; //cur->parent=cr;return cr;
}
举个简单的例子:

x是新插入的节点,此时 R 的平衡因子为> 1,这种情况可以叫做LL型,R 的左子树RL 的左子树新插入了节点,平衡操作为节点 R 右旋
 然后就平衡了 🤠
然后就平衡了 🤠
再举一个例子:

R 的平衡因子仍然是 2,但是插入的节点在 RL 的右子树,这种情况可以叫做 LR 型,需要进行两次旋转操作然后平衡
首先给 RL 左旋:
 聪明的你一定发现了,左旋之后变成了 LL 型,所以接下来再给 R 进行一次右旋操作:
聪明的你一定发现了,左旋之后变成了 LL 型,所以接下来再给 R 进行一次右旋操作:
 于是又平衡了
于是又平衡了
当然,LR 型包含了三种情况,这里是RRR节点的平衡因子为-1,还有0 1这两种,但是本质上都是通过左旋RL节点,变成LL型,然后右旋R最终平衡
至于RR,RL型,和LL,LR是对称操作,这里不再赘述
代码实现
懒得写…以后补
AVL与普通BST有区别的操作在于插入和删除时,需要对可能受影响的节点平衡,可能受影响的节点,实际上就是操作节点的所有祖先节点,因为这些节点的平衡因子会发生变化(子树高度变了)
Conclusion
实际上,AVL就是一棵特殊的BST,只是对高度进行了限制,那么,AVL的应用场景在什么地方捏?
传统的BST很容易退化成一条链,这时的查找复杂度就变成了O(n),而AVL通过平衡,保证树整体结构相对对称,查找复杂度总是O(logn)
不过由于平衡操作很耗性能,所以只适合少量增删节点,大量查询的场景
B tree
B 你妈
Content
Part 1-Introduction and Setting up the REPL
作为一个网络开发者,我每天都在工作中使用关联性数据库,但是它们对于我来说是一个黑盒子.我有一些疑惑:
- 数据存储形式是什么?(内存和磁盘)
- 数据什么时候从内存中移动到磁盘?
- 为什么每个表只能有一个主 key?
- 回滚事务是如何工作的?
- 索引是如何格式化的?
- 全表扫描何时以及如何发生?
- 即将执行的语句以什么格式储存?
换句话说就是,数据库是如何 工作 的?
为了把事情弄清楚,我正在从头开始写一个数据库.它以 sqlite 为模板,因为它被设计为小体积,功能比 MySql 或 PostgreSQL 少,所以我更有希望理解它.整个数据库被存储在一个文件中!
Sqlite
在 Sqlite 网站上有许多 关于 sqilite 的内部结构的文章,此外我有一份资料SQLite Database System:Design and Implementation.
sqlite 结构(howitworks.wiki)
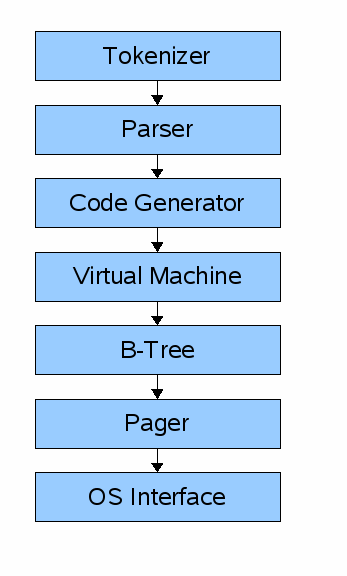
一次查询通过一系列组件来检索或修改数据.前端 包括:
- tokenizer
- parser
- code generator
前端的输入是一个 SQL 查询,输出是 sqlite 虚拟字节码(本质上是一个可被数据库执行的编译程序).
后端 包括:
- virtual machine
- B-tree
- pager
- os interface
虚拟机 将前端生成的字节码当作指令.它可以在一个或多个表格或索引上执行操作,每个表或索引都被存储在一个叫做B-tree的数据结构中.虚拟机本质上是一个 switch 语句,条件是字节码指令.
每个B-tree包括许多节点.每个节点的长度为一页.B-tree可以从磁盘中读取一页或者通过向pager发出指令然后将一页存储到磁盘上.
pager 接收命令以读取或写入数据页.它负责在合适的位置读取/写入数据,还将最近获取的几页的缓存保存在内存中,并且决定那些页何时被写回磁盘.
os interface(系统接口) 层根据 sqlite 被编译的平台而有所区别.在本教程中,我不打算支持多个操作系统.
千里之行,始于足下,所以让我们以更直接的方式开始:the REPL(read-eval-print loop)
Making a Simple REPL
当从命令行执行 sqlite 时,会进入一个读取-执行-输出循环:
~ sqlite3
SQLite version 3.16.0 2016-11-04 19:09:39
Enter “.help” for usage hints.
Connected to a transient in-memory database.
Use “.open FILENAME” to reopen on a persistent database.
sqlite> create table users (id int, username varchar(255), email varchar(255));
sqlite> .tables
users
sqlite> .exit
~
为了实现这个,我们的 main 函数将会有一个无止境的循环,打印提示,获取一行输入,然后执行这行输入:
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
cout<<"Unrecognized command "<<
<<input_buffer->buffer<<endl;
}
}
}
我们将InputBuffer定义为一个小包装器以便存储和getline(ref)交互时的状态.
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer(){
InputBuffer* input_buffer=InputBuffer* malloc(sizeof(InputBuffer));
input_buffer->buffer=NULL;
input_buffer->buffer_length=0;
input_buffer->input_length=0;
return input_buffer;
}
然后,print_prompt()给用户打印提示,在读取一行输入之前.
void print_prompt(){cout<<"db > ";}
为了读取一行输入,使用getline:
ssize_t getline(char **lineptr,size_t *n,FILE *stream);
lineptr:一个指针,指向我们用来指向包含读取的行的缓冲区的变量.如果在调用getline()之前*lineptr被设为NULL,那么getline()将会分配一个缓冲区用来存储行,这个缓冲区应该由用户释放,即使getline()调用失败.
n:一个指针,指向我们用来存储分配的缓冲区的大小的变量.
stream:用来读取的输入流.我们将从标准输入流中读取.
return value:读取的字节数,可能小于缓冲区的大小.
我们让getline读取的行存储在input_buffer->buffer,缓冲区大小是input_buffer->buffer_length,返回值存储在input_buffer->input_length
buffer的初始值为null,所以getline会分配足够的空间来保存输入行,然后让buffer指向该空间.
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE); //define EXIT_FAILURE 1
}
// 忽略换行符
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0; //c语言字符串结束标志为'\0',数值为0
}
现在是时候定义一个函数用来释放分配给InputBuffer *实例以及成员变量buffer的空间了(调用read_input的时候getline给input_buffer->buffer分配了内存).
void close_input_buffer(InputBuffer* input_buffer){
free(input_buffer->buffer); //显然,是用堆分配的空间
free(input_buffer);
}
最后,解析然后执行命令.目前只有一个命令可以被识别:.exit,用来终止程序,如果不是.exit就打印错误消息然后继续循环.
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
现在尝试运行它吧~
~ ./db
db > .tables
Unrecognized command ‘.tables’.
db > .exit
~
好了,我们得到了一个有用的REPL.在下一部分,将要开发我们的命令语言.
顺便,这是这部分的全部代码:
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
void print_prompt() { printf("db > "); }
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
// Ignore trailing newline
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}
void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer->buffer);
free(input_buffer);
}
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}
Part 2 - World’s Simplest SQL Compiler and Virtual Machine
我们正在克隆一份sqlite.sqlite的前端是一个SQL编译器,用来解析输入的字符串然后输出一种叫做bytecode(字节码)的内部表示.
bytecode被传入虚拟机,然后由虚拟机执行.
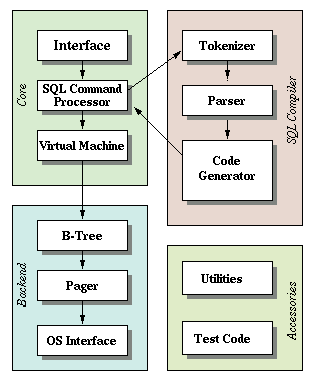
将事情分成这样的两步有2个好处:
- 减少每一部分的复杂性(e.g. 虚拟机不关心语法错误)
- Allows compiling common queries once and caching the bytecode for improved performance.
考虑到这一点,让我们重构main函数并且在过程中支持两个新的关键词:
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
- if (strcmp(input_buffer->buffer, ".exit") == 0) {
- exit(EXIT_SUCCESS);
- } else {
- printf("Unrecognized command '%s'.\n", input_buffer->buffer);
+ if (input_buffer->buffer[0] == '.') {
+ switch (do_meta_command(input_buffer)) {
+ case (META_COMMAND_SUCCESS):
+ continue;
+ case (META_COMMAND_UNRECOGNIZED_COMMAND):
+ cout<<"Unrecognized command: "<<input_buffer->buffer<<endl;
+ continue;
+ }
}
+
+ Statement statement;
+ switch (prepare_statement(input_buffer, &statement)) {
+ case (PREPARE_SUCCESS):
+ break;
+ case (PREPARE_UNRECOGNIZED_STATEMENT):
+ cout<<"Unrecognized keyword at start of: "<<input_buffer->buffer<<endl;
+ continue;
+ }
+
+ execute_statement(&statement);
+ cout<<"Executed."<<endl;
}
}
非SQL语句像是.exit被称作 元命令.元命令以.开始,因此我们检查并在单独的函数中处理元命令.
然后,加一步用来把输入行转换为语句的内部表示.This is our hacky version of the sqlite front-end.
最后,把准备好的语句传递给execute_statement.这个函数最终会成为我们的虚拟机.
注意两个新函数返回的是表示成功或失败的枚举变量:
typedef enum { META_COMMAND_SUCCESS, META_COMMAND_UNRECOGNIZED_COMMAND } MetaCommandResult; typedef enum { PREPARE_SUCCESS, PREPARE_UNRECOGNIZED_STATEMENT } PrepareResult;
“Unrecognized statement”?这有点像一个 exception.我不太喜欢使用exception(而且C甚至都不支持),所以我在任何可行的地方都是用enum result code.如果switch语句没有处理其中一个枚举成员,C编译器会报错,所以我们可以更有信心地处理函数的每个结果.预计未来会添加更多result code.
do_meta_command只是现有功能的一个装饰器,用来给更多命令预留空间.
MetaCommandResult do_meta_command(InputBuffer* input_buffer) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
}
目前的prepared statement只包含一个有两个成员的枚举变量,因为我们允许statements有参数,它将包含更多数据.
typedef enum { STATEMENT_INSERT, STATEMENT_SELECT } StatementType;
typedef struct {
StatementType type;
} Statement;
prepare_statement(我们的”SQL编译器”)现在还不能理解SQL语句.实际上它只能理解两个词:
PrepareResult prepare_statement(InputBuffer* input_buffer,
Statement* statement) {
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
statement->type = STATEMENT_INSERT;
return PREPARE_SUCCESS;
}
if (strcmp(input_buffer->buffer, "select") == 0) {
statement->type = STATEMENT_SELECT;
return PREPARE_SUCCESS;
}
return PREPARE_UNRECOGNIZED_STATEMENT;
}
注意我们使用的是strncmp来比较字符串因为insert单词后面跟着数据.(e.g. insert 1 cstack foo@bar.com)
最后,execute_statement包含一些stubs:
void execute_statement(Statement* statement) {
switch (statement->type) {
case (STATEMENT_INSERT):
printf("This is where we would do an insert.\n");
break;
case (STATEMENT_SELECT):
printf("This is where we would do a select.\n");
break;
}
}
注意函数不返回任何错误码,因为目前还不会出现错误.
重构之后,现在可以识别两个新关键字了!
~ ./db
db > insert foo bar
This is where we would do an insert.
Executed.
db > delete foo
Unrecognized keyword at start of ‘delete foo’.
db > select
This is where we would do a select.
Executed.
db > .tables
Unrecognized command ‘.tables’
db > .exit
~
我们数据库程序的骨架正在逐步构建…如果它能够存储数据那不是更好吗?在下一章,我们将会实现insert和select,创建世界上最糟糕~的数据存储.顺便,这里有本章的所有改动:
@@ -10,6 +10,23 @@ struct InputBuffer_t {
} InputBuffer;
+typedef enum {
+ META_COMMAND_SUCCESS,
+ META_COMMAND_UNRECOGNIZED_COMMAND
+} MetaCommandResult;
+
+typedef enum { PREPARE_SUCCESS, PREPARE_UNRECOGNIZED_STATEMENT } PrepareResult;
+
+typedef enum { STATEMENT_INSERT, STATEMENT_SELECT } StatementType;
+
+typedef struct {
+ StatementType type;
+} Statement;
+
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
@@ -40,17 +57,67 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
+MetaCommandResult do_meta_command(InputBuffer* input_buffer) {
+ if (strcmp(input_buffer->buffer, ".exit") == 0) {
+ close_input_buffer(input_buffer);
+ exit(EXIT_SUCCESS);
+ } else {
+ return META_COMMAND_UNRECOGNIZED_COMMAND;
+ }
+}
+
+PrepareResult prepare_statement(InputBuffer* input_buffer,
+ Statement* statement) {
+ if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+ statement->type = STATEMENT_INSERT;
+ return PREPARE_SUCCESS;
+ }
+ if (strcmp(input_buffer->buffer, "select") == 0) {
+ statement->type = STATEMENT_SELECT;
+ return PREPARE_SUCCESS;
+ }
+
+ return PREPARE_UNRECOGNIZED_STATEMENT;
+}
+
+void execute_statement(Statement* statement) {
+ switch (statement->type) {
+ case (STATEMENT_INSERT):
+ printf("This is where we would do an insert.\n");
+ break;
+ case (STATEMENT_SELECT):
+ printf("This is where we would do a select.\n");
+ break;
+ }
+}
+
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
- if (strcmp(input_buffer->buffer, ".exit") == 0) {
- close_input_buffer(input_buffer);
- exit(EXIT_SUCCESS);
- } else {
- printf("Unrecognized command '%s'.\n", input_buffer->buffer);
+ if (input_buffer->buffer[0] == '.') {
+ switch (do_meta_command(input_buffer)) {
+ case (META_COMMAND_SUCCESS):
+ continue;
+ case (META_COMMAND_UNRECOGNIZED_COMMAND):
+ printf("Unrecognized command '%s'\n", input_buffer->buffer);
+ continue;
+ }
}
+
+ Statement statement;
+ switch (prepare_statement(input_buffer, &statement)) {
+ case (PREPARE_SUCCESS):
+ break;
+ case (PREPARE_UNRECOGNIZED_STATEMENT):
+ printf("Unrecognized keyword at start of '%s'.\n",
+ input_buffer->buffer);
+ continue;
+ }
+
+ execute_statement(&statement);
+ printf("Executed.\n");
}
}
Part3 - An In-Memory,Append-Only,Single-Table Database
我们先实现最基础的功能,并给数据库添加一些限制.目前来说,数据库将:
- 支持两种操作: 插入一行然后打印所有行.
- 只保存在内存中(而不是磁盘)
- 支持单个,硬编码的表
我们的硬编码表将会存储用户,看起来像这样:

这是一个简单的模板,但是支持多种数据类型和长度可变的字符串.
insert语句看起来像这样:
insert 1 cstack foo@bar.com
这意味着我们需要扩展prepare_statement函数以解析参数
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
statement->type = STATEMENT_INSERT;
+ int args_assigned = sscanf(
+ input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
+ statement->row_to_insert.username, statement->row_to_insert.email);
+ if (args_assigned < 3) {
+ return PREPARE_SYNTAX_ERROR;
+ }
return PREPARE_SUCCESS;
}
if (strcmp(input_buffer->buffer, "select") == 0) {
我们把解析得到的参数放进statement对象的新成员Row中.
+#define COLUMN_USERNAME_SIZE 32
+#define COLUMN_EMAIL_SIZE 255
+typedef struct {
+ uint32_t id;
+ char username[COLUMN_USERNAME_SIZE];
+ char email[COLUMN_EMAIL_SIZE];
+} Row;
+
typedef struct {
StatementType type;
+ Row row_to_insert; // only used by insert statement
} Statement;
现在我们需要把数据拷贝到表示表的数据结构中.SQLite使用B-tree以实现快速查找,插入和删除.我们一开始先用简单点的数据结构.类似一棵B-tree,它将行存进页中,但是页并不以树的形式组织,而是以列表的形式.
这是我的想法:
- 将行存储在叫做页的内存块
- 每一页存储尽可能多的行
- 每一页中行被序列化成紧凑的表现形式
- 页只在需要的时候分配
- 维护一个定长数组,数组数据是指向页的指针
首先我们定义行的紧凑的表现形式:
+#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
+
+const uint32_t ID_SIZE = size_of_attribute(Row, id);
+const uint32_t USERNAME_SIZE = size_of_attribute(Row, username);
+const uint32_t EMAIL_SIZE = size_of_attribute(Row, email);
+const uint32_t ID_OFFSET = 0;
+const uint32_t USERNAME_OFFSET = ID_OFFSET + ID_SIZE;
+const uint32_t EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE;
+const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
译者注:
对于那个奇形怪状的宏
#define size_of_attribute(Struct,Attribute)作用是计算结构体成员变量的大小
举个例子,宏展开后会是这样:
sizeof(((Row*)0)->email)0被强制转化为Row指针,然后0就可以访问成员变量.
这个操作不会创建结构体实体,因为没有用
malloc开辟空间,所以0实际上是一个野指针,但是sizeof不在乎是否野指针,它只需要指针指向的变量类型就可以判断出大小.(sizeof在编译时运行)
这意味着一个序列化的行的布局看起来像这样:

We also need code to convert to and from the compact representation.
+void serialize_row(Row* source, void* destination) {
+ memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
+ memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
+ memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+}
+
+void deserialize_row(void* source, Row* destination) {
+ memcpy(&(destination->id), source + ID_OFFSET, ID_SIZE);
+ memcpy(&(destination->username), source + USERNAME_OFFSET, USERNAME_SIZE);
+ memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
+}
接下来,定义Table结构体,指向存储着行的页,以及追踪总行数:
+const uint32_t PAGE_SIZE = 4096;
+#define TABLE_MAX_PAGES 100
+const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
+const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+
+typedef struct {
+ uint32_t num_rows;
+ void* pages[TABLE_MAX_PAGES];
+} Table;
每页大小为4KB,因为这和大多数计算机架构的虚拟内存系统使用的页一致.也就是说我们数据库的页大小和操作系统使用的页大小相同.操作系统将会以完整的单元将页移入和移出内存,而不是拆散它们.
我把最大分配的页的数量设置为一个随意的数字-100.当我们切换到B-Tree结构后,我们数据库的最大大小将仅受限于一个文件的最大大小.(尽管我们仍会限制在内存中的页的数量)
行不应该穿过页的边界.因为页在内存中的位置很可能不是彼此相邻的,这个假设让写入/读取行更容易些.(注: 简单解释一下,如果每页行数不是向下取整,可能会出现一行被分割到了逻辑上相连的两页上,但由于页的空间是malloc函数分配的,因此物理地址不一定相连,需要额外处理这种情况.)
说到行的读写,下面是我们如何确定在内存的什么位置读取/写入具体行:
+void* row_slot(Table* table, uint32_t row_num) {
+ uint32_t page_num = row_num / ROWS_PER_PAGE;
+ void* page = table->pages[page_num];
+ if (page == NULL) {
+ // Allocate memory only when we try to access page
+ page = table->pages[page_num] = malloc(PAGE_SIZE);
+ }
+ uint32_t row_offset = row_num % ROWS_PER_PAGE;
+ uint32_t byte_offset = row_offset * ROW_SIZE;
+ return page + byte_offset;
+}
然后是实现execute_statement函数,可以从table结构体读取/写入数据.
-void execute_statement(Statement* statement) {
+ExecuteResult execute_insert(Statement* statement, Table* table) {
+ if (table->num_rows >= TABLE_MAX_ROWS) {
+ return EXECUTE_TABLE_FULL;
+ }
+
+ Row* row_to_insert = &(statement->row_to_insert);
+
+ serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ table->num_rows += 1;
+
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_select(Statement* statement, Table* table) {
+ Row row;
+ for (uint32_t i = 0; i < table->num_rows; i++) {
+ deserialize_row(row_slot(table, i), &row);
+ print_row(&row);
+ }
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_statement(Statement* statement, Table* table) {
switch (statement->type) {
case (STATEMENT_INSERT):
- printf("This is where we would do an insert.\n");
- break;
+ return execute_insert(statement, table);
case (STATEMENT_SELECT):
- printf("This is where we would do a select.\n");
- break;
+ return execute_select(statement, table);
}
}
注: 原作者好像漏了
enum ExecuteResult而print_row()补上(我自己的实现)
typedef enum{ EXECUTE_SUCCESS, EXECUTE_TABLE_FULL } ExecuteResult; void print_row(Row* row){ cout<<"ID: "<<row->id<<endl <<"username: "<<row->username<<endl <<"emal: "<<row->email<<endl; }
最后,我们需要初始化列表,创建各自的内存释放函数以及处理一些错误情况:
+ Table* new_table() {
+ Table* table = (Table*)malloc(sizeof(Table));
+ table->num_rows = 0;
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ table->pages[i] = NULL;
+ }
+ return table;
+}
+
+void free_table(Table* table) {
+ for (int i = 0; table->pages[i]; i++) {
+ free(table->pages[i]);
+ }
+ free(table);
+}
int main(int argc, char* argv[]) {
+ Table* table = new_table();
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
@@ -105,13 +203,22 @@ int main(int argc, char* argv[]) {
switch (prepare_statement(input_buffer, &statement)) {
case (PREPARE_SUCCESS):
break;
+ case (PREPARE_SYNTAX_ERROR):
+ printf("Syntax error. Could not parse statement.\n");
+ continue;
case (PREPARE_UNRECOGNIZED_STATEMENT):
printf("Unrecognized keyword at start of '%s'.\n",
input_buffer->buffer);
continue;
}
- execute_statement(&statement);
- printf("Executed.\n");
+ switch (execute_statement(&statement, table)) {
+ case (EXECUTE_SUCCESS):
+ printf("Executed.\n");
+ break;
+ case (EXECUTE_TABLE_FULL):
+ printf("Error: Table full.\n");
+ break;
+ }
}
}
注:
对于switch中的
continue & break简单来说,
break只退出switch语句本身如果
switch是在循环体中,那么continue会跳过本次循环(即不执行switch后面的语句).
做完这些后我们就可以将数据保存到数据库里辣!
~ ./db
db > insert 1 cstack foo@bar.com
Executed.
db > insert 2 bob bob@example.com
Executed.
db > select
(1, cstack, foo@bar.com)
(2, bob, bob@example.com)
Executed.
db > insert foo bar 1
Syntax error. Could not parse statement.
db > .exit
~
现在是写一些测试的最好时机喔,理由如下:
- We’re planning to dramatically change the data structure storing our table, and tests would catch regressions.
- 有一些边际情况我们还没有手动测试(e.g. 表被填满了)
我们将在下一章解决这些问题.这里有本章代码的全部改动:
@@ -2,6 +2,7 @@
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
+#include <stdint.h>
typedef struct {
char* buffer;
@@ -10,6 +11,105 @@ typedef struct {
} InputBuffer;
+typedef enum { EXECUTE_SUCCESS, EXECUTE_TABLE_FULL } ExecuteResult;
+
+typedef enum {
+ META_COMMAND_SUCCESS,
+ META_COMMAND_UNRECOGNIZED_COMMAND
+} MetaCommandResult;
+
+typedef enum {
+ PREPARE_SUCCESS,
+ PREPARE_SYNTAX_ERROR,
+ PREPARE_UNRECOGNIZED_STATEMENT
+ } PrepareResult;
+
+typedef enum { STATEMENT_INSERT, STATEMENT_SELECT } StatementType;
+
+#define COLUMN_USERNAME_SIZE 32
+#define COLUMN_EMAIL_SIZE 255
+typedef struct {
+ uint32_t id;
+ char username[COLUMN_USERNAME_SIZE];
+ char email[COLUMN_EMAIL_SIZE];
+} Row;
+
+typedef struct {
+ StatementType type;
+ Row row_to_insert; //only used by insert statement
+} Statement;
+
+#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
+
+const uint32_t ID_SIZE = size_of_attribute(Row, id);
+const uint32_t USERNAME_SIZE = size_of_attribute(Row, username);
+const uint32_t EMAIL_SIZE = size_of_attribute(Row, email);
+const uint32_t ID_OFFSET = 0;
+const uint32_t USERNAME_OFFSET = ID_OFFSET + ID_SIZE;
+const uint32_t EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE;
+const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
+
+const uint32_t PAGE_SIZE = 4096;
+#define TABLE_MAX_PAGES 100
+const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
+const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+
+typedef struct {
+ uint32_t num_rows;
+ void* pages[TABLE_MAX_PAGES];
+} Table;
+
+void print_row(Row* row) {
+ printf("(%d, %s, %s)\n", row->id, row->username, row->email);
+}
+
+void serialize_row(Row* source, void* destination) {
+ memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
+ memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
+ memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+}
+
+void deserialize_row(void *source, Row* destination) {
+ memcpy(&(destination->id), source + ID_OFFSET, ID_SIZE);
+ memcpy(&(destination->username), source + USERNAME_OFFSET, USERNAME_SIZE);
+ memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
+}
+
+void* row_slot(Table* table, uint32_t row_num) {
+ uint32_t page_num = row_num / ROWS_PER_PAGE;
+ void *page = table->pages[page_num];
+ if (page == NULL) {
+ // Allocate memory only when we try to access page
+ page = table->pages[page_num] = malloc(PAGE_SIZE);
+ }
+ uint32_t row_offset = row_num % ROWS_PER_PAGE;
+ uint32_t byte_offset = row_offset * ROW_SIZE;
+ return page + byte_offset;
+}
+
+Table* new_table() {
+ Table* table = (Table*)malloc(sizeof(Table));
+ table->num_rows = 0;
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ table->pages[i] = NULL;
+ }
+ return table;
+}
+
+void free_table(Table* table) {
+ for (int i = 0; table->pages[i]; i++) {
+ free(table->pages[i]);
+ }
+ free(table);
+}
+
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = (InputBuffer*)malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
@@ -40,17 +140,105 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
+MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
+ if (strcmp(input_buffer->buffer, ".exit") == 0) {
+ close_input_buffer(input_buffer);
+ free_table(table);
+ exit(EXIT_SUCCESS);
+ } else {
+ return META_COMMAND_UNRECOGNIZED_COMMAND;
+ }
+}
+
+PrepareResult prepare_statement(InputBuffer* input_buffer,
+ Statement* statement) {
+ if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+ statement->type = STATEMENT_INSERT;
+ int args_assigned = sscanf(
+ input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
+ statement->row_to_insert.username, statement->row_to_insert.email
+ );
+ if (args_assigned < 3) {
+ return PREPARE_SYNTAX_ERROR;
+ }
+ return PREPARE_SUCCESS;
+ }
+ if (strcmp(input_buffer->buffer, "select") == 0) {
+ statement->type = STATEMENT_SELECT;
+ return PREPARE_SUCCESS;
+ }
+
+ return PREPARE_UNRECOGNIZED_STATEMENT;
+}
+
+ExecuteResult execute_insert(Statement* statement, Table* table) {
+ if (table->num_rows >= TABLE_MAX_ROWS) {
+ return EXECUTE_TABLE_FULL;
+ }
+
+ Row* row_to_insert = &(statement->row_to_insert);
+
+ serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ table->num_rows += 1;
+
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_select(Statement* statement, Table* table) {
+ Row row;
+ for (uint32_t i = 0; i < table->num_rows; i++) {
+ deserialize_row(row_slot(table, i), &row);
+ print_row(&row);
+ }
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_statement(Statement* statement, Table *table) {
+ switch (statement->type) {
+ case (STATEMENT_INSERT):
+ return execute_insert(statement, table);
+ case (STATEMENT_SELECT):
+ return execute_select(statement, table);
+ }
+}
+
int main(int argc, char* argv[]) {
+ Table* table = new_table();
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
- if (strcmp(input_buffer->buffer, ".exit") == 0) {
- close_input_buffer(input_buffer);
- exit(EXIT_SUCCESS);
- } else {
- printf("Unrecognized command '%s'.\n", input_buffer->buffer);
+ if (input_buffer->buffer[0] == '.') {
+ switch (do_meta_command(input_buffer, table)) {
+ case (META_COMMAND_SUCCESS):
+ continue;
+ case (META_COMMAND_UNRECOGNIZED_COMMAND):
+ printf("Unrecognized command '%s'\n", input_buffer->buffer);
+ continue;
+ }
+ }
+
+ Statement statement;
+ switch (prepare_statement(input_buffer, &statement)) {
+ case (PREPARE_SUCCESS):
+ break;
+ case (PREPARE_SYNTAX_ERROR):
+ printf("Syntax error. Could not parse statement.\n");
+ continue;
+ case (PREPARE_UNRECOGNIZED_STATEMENT):
+ printf("Unrecognized keyword at start of '%s'.\n",
+ input_buffer->buffer);
+ continue;
+ }
+
+ switch (execute_statement(&statement, table)) {
+ case (EXECUTE_SUCCESS):
+ printf("Executed.\n");
+ break;
+ case (EXECUTE_TABLE_FULL):
+ printf("Error: Table full.\n");
+ break;
}
}
}
Part 4 - Our First Tests (and Bugs)
我们已经可以向数据库中插入行然后打印所有行了.让我们测试一下目前实现的功能.
我将会使用rspec来测试因为我比较熟悉它,并且它的语法相当友好.
我将定义一个辅助工具来给数据库发送命令然后断言输出:
describe 'database' do
def run_script(commands)
raw_output = nil
IO.popen("./db", "r+") do |pipe|
commands.each do |command|
pipe.puts command
end
pipe.close_write
# Read entire output
raw_output = pipe.gets(nil)
end
raw_output.split("\n")
end
it 'inserts and retrieves a row' do
result = run_script([
"insert 1 user1 person1@example.com",
"select",
".exit",
])
expect(result).to match_array([
"db > Executed.",
"db > (1, user1, person1@example.com)",
"Executed.",
"db > ",
])
end
end
测试结果:
rspec test.rb
Finished in 0.00871 seconds (files took 0.09506 seconds to load)
1 example, 0 failures
是时候测试插入大量行了:
it 'prints error message when table is full' do
script = (1..1401).map do |i|
"insert #{i} user#{i} person#{i}@example.com"
end
script << ".exit"
result = run_script(script)
expect(result[-2]).to eq('db > Error: Table full.')
end
重新测试…
Finished in 0.01553 seconds (files took 0.08156 seconds to load)
2 examples, 0 failures
测试成功!数据库目前可以保存1400行因为我们设置了最大页数为100,每页可以存储14行.
检查一下目前的代码,可以发现我们没有仔细处理文本字段,用这个例子测试:
it 'allows inserting strings that are the maximum length' do
long_username = "a"*32
long_email = "a"*255
script = [
"insert 1 #{long_username} #{long_email}",
"select",
".exit",
]
result = run_script(script)
expect(result).to match_array([
"db > Executed.",
"db > (1, #{long_username}, #{long_email})",
"Executed.",
"db > ",
])
end
Faliures:
1) database allows inserting strings that are the maximum length
Failure/Error: raw_output.split("\n")
ArgumentError:
invalid byte sequence in UTF-8
# ./spec/main_spec.rb:14:in `split'
# ./spec/main_spec.rb:14:in `run_script'
# ./spec/main_spec.rb:48:in `block (2 levels) in <top (required)>'
如果我们手动测试,打印出来的结果会有一些奇怪的字符:
db > insert 1 aaaaa... aaaaa...
Executed.
db > select
(1, aaaaa...aaa\, aaaaa...aaa\)
Executed.
db >
发生了什么?如果查看Row的定义,我们可以发现给username分配了32字节,email 255字节.但是C strings应该以null字符('\0')结尾,而我们并没有给这一位分配空间.解决办法是额外分配一个字节:
const uint32_t COLUMN_EMAIL_SIZE = 255;
typedef struct {
uint32_t id;
- char username[COLUMN_USERNAME_SIZE];
- char email[COLUMN_EMAIL_SIZE];
+ char username[COLUMN_USERNAME_SIZE + 1];
+ char email[COLUMN_EMAIL_SIZE + 1];
} Row;
然后问题被修复了:
Finished in 0.0188 seconds (files took 0.08516 seconds to load)
3 examples, 0 failures
我们不应该允许插入的username或email超过最大长度,这种情况下结果应该像这样:
it 'prints error message if strings are too long' do
long_username = "a"*33
long_email = "a"*256
script = [
"insert 1 #{long_username} #{long_email}",
"select",
".exit",
]
result = run_script(script)
expect(result).to match_array([
"db > String is too long.",
"db > Executed.",
"db > ",
])
end
为了实现这个我们需要修改解析器.提醒一下,我们解析输入用的是scanf():
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
statement->type = STATEMENT_INSERT;
int args_assigned = sscanf(
input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
statement->row_to_insert.username, statement->row_to_insert.email);
//sscanf只是将输入从stdin变成string
if (args_assigned < 3) {
return PREPARE_SYNTAX_ERROR;
}
return PREPARE_SUCCESS;
}
但是scanf有一些缺点.如果读取的长度大于目标缓冲区的长度,会造成缓冲区移除并将多余的数据写入预期之外的地方.我们希望在将数据copy到Row结构体内之前先检查每个字符串的长度.为了实现这个功能,我们需要用空格将输入分割成几个部分.
译者注: 事实上,不完全正确.
可以用格式字符串限制长度 scanf(“%
wids”,s1)例如限制字符串长度为100
scanf("%100s",s1)遇到
blank或者读取100个字符就会结束.不过需要自己确保s1有额外空间保存\0字符
blank: 指 空格(space),制表符(Tab),回车符(‘\n’).scanf还有很多特性,比如会忽略开头的所有空白符,%c返回键盘缓冲区的第一个字符(包括回车)…
感兴趣自行查阅
使用strtok()来实现这个功能:
+PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) {
+ statement->type = STATEMENT_INSERT;
+
+ char* keyword = strtok(input_buffer->buffer, " ");
+ char* id_string = strtok(NULL, " ");
+ char* username = strtok(NULL, " ");
+ char* email = strtok(NULL, " ");
+
+ if (id_string == NULL || username == NULL || email == NULL) {
+ return PREPARE_SYNTAX_ERROR;
+ }
+
+ int id = atoi(id_string);
+ if (strlen(username) > COLUMN_USERNAME_SIZE) {
+ return PREPARE_STRING_TOO_LONG;
+ }
+ if (strlen(email) > COLUMN_EMAIL_SIZE) {
+ return PREPARE_STRING_TOO_LONG;
+ }
+
+ statement->row_to_insert.id = id;
+ strcpy(statement->row_to_insert.username, username);
+ strcpy(statement->row_to_insert.email, email);
+
+ return PREPARE_SUCCESS;
+}
+
PrepareResult prepare_statement(InputBuffer* input_buffer,
Statement* statement) {
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+ return prepare_insert(input_buffer, statement);
- statement->type = STATEMENT_INSERT;
- int args_assigned = sscanf(
- input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
- statement->row_to_insert.username, statement->row_to_insert.email);
- if (args_assigned < 3) {
- return PREPARE_SYNTAX_ERROR;
- }
- return PREPARE_SUCCESS;
}
strtok在遇到分割字符(我们的例子中是空格)时就插入NULL字符,从而将输入缓冲分割成了子字符串.返回值为指向子串开头的指针.
注: 简要说明一下
strtok的原理.
strtok维护一个静态局部指针变量next,非分割字符与分割字符之间的子串叫做token,如果strtok在输入流中找到token,返回指向token开头的指针,然后next指向token之后的分割字符的后一个字节.如果
strtok(const char* str,const char* delimiter)的第一个参数str为NULL,那么相当于把next赋值给str(即从上一次调用时的token之后开始)
然后用strlen()判断字符串是否超出长度限制.
我们可以像处理其它错误码一样处理PREPARE_STRING_TOO_LONG:
enum PrepareResult_t {
PREPARE_SUCCESS,
+ PREPARE_STRING_TOO_LONG,
PREPARE_SYNTAX_ERROR,
PREPARE_UNRECOGNIZED_STATEMENT
};
switch (prepare_statement(input_buffer, &statement)) {
case (PREPARE_SUCCESS):
break;
+ case (PREPARE_STRING_TOO_LONG):
+ printf("String is too long.\n");
+ continue;
case (PREPARE_SYNTAX_ERROR):
printf("Syntax error. Could not parse statement.\n");
continue;
做完这些就可以通过测试辣~
Finished in 0.02284 seconds (files took 0.116 seconds to load)
4 examples, 0 failures
进行到现在,我们不妨处理更多错误情况:
it 'prints an error message if id is negative' do
script = [
"insert -1 cstack foo@bar.com",
"select",
".exit",
]
result = run_script(script)
expect(result).to match_array([
"db > ID must be positive.",
"db > Executed.",
"db > ",
])
end
enum PrepareResult_t {
PREPARE_SUCCESS,
+ PREPARE_NEGATIVE_ID,
PREPARE_STRING_TOO_LONG,
PREPARE_SYNTAX_ERROR,
PREPARE_UNRECOGNIZED_STATEMENT
@@ -148,9 +147,6 @@ PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) {
}
int id = atoi(id_string);
+ if (id < 0) {
+ return PREPARE_NEGATIVE_ID;
+ }
if (strlen(username) > COLUMN_USERNAME_SIZE) {
return PREPARE_STRING_TOO_LONG;
}
@@ -230,9 +226,6 @@ int main(int argc, char* argv[]) {
switch (prepare_statement(input_buffer, &statement)) {
case (PREPARE_SUCCESS):
break;
+ case (PREPARE_NEGATIVE_ID):
+ printf("ID must be positive.\n");
+ continue;
case (PREPARE_STRING_TOO_LONG):
printf("String is too long.\n");
continue;
好了,目前来说测试已经足够了.下一章是非常重要的功能:保存!我们将会把数据库保存到文件中然后读取到内存中.
这会很棒的.
这里是这章节代码的全部改动:
@@ -22,6 +22,8 @@
enum PrepareResult_t {
PREPARE_SUCCESS,
+ PREPARE_NEGATIVE_ID,
+ PREPARE_STRING_TOO_LONG,
PREPARE_SYNTAX_ERROR,
PREPARE_UNRECOGNIZED_STATEMENT
};
@@ -34,8 +36,8 @@
#define COLUMN_EMAIL_SIZE 255
typedef struct {
uint32_t id;
- char username[COLUMN_USERNAME_SIZE];
- char email[COLUMN_EMAIL_SIZE];
+ char username[COLUMN_USERNAME_SIZE + 1];
+ char email[COLUMN_EMAIL_SIZE + 1];
} Row;
@@ -150,18 +152,40 @@ MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
}
}
-PrepareResult prepare_statement(InputBuffer* input_buffer,
- Statement* statement) {
- if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) {
statement->type = STATEMENT_INSERT;
- int args_assigned = sscanf(
- input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
- statement->row_to_insert.username, statement->row_to_insert.email
- );
- if (args_assigned < 3) {
+
+ char* keyword = strtok(input_buffer->buffer, " ");
+ char* id_string = strtok(NULL, " ");
+ char* username = strtok(NULL, " ");
+ char* email = strtok(NULL, " ");
+
+ if (id_string == NULL || username == NULL || email == NULL) {
return PREPARE_SYNTAX_ERROR;
}
+
+ int id = atoi(id_string);
+ if (id < 0) {
+ return PREPARE_NEGATIVE_ID;
+ }
+ if (strlen(username) > COLUMN_USERNAME_SIZE) {
+ return PREPARE_STRING_TOO_LONG;
+ }
+ if (strlen(email) > COLUMN_EMAIL_SIZE) {
+ return PREPARE_STRING_TOO_LONG;
+ }
+
+ statement->row_to_insert.id = id;
+ strcpy(statement->row_to_insert.username, username);
+ strcpy(statement->row_to_insert.email, email);
+
return PREPARE_SUCCESS;
+
+}
+PrepareResult prepare_statement(InputBuffer* input_buffer,
+ Statement* statement) {
+ if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+ return prepare_insert(input_buffer, statement);
}
if (strcmp(input_buffer->buffer, "select") == 0) {
statement->type = STATEMENT_SELECT;
@@ -223,6 +247,12 @@ int main(int argc, char* argv[]) {
switch (prepare_statement(input_buffer, &statement)) {
case (PREPARE_SUCCESS):
break;
+ case (PREPARE_NEGATIVE_ID):
+ printf("ID must be positive.\n");
+ continue;
+ case (PREPARE_STRING_TOO_LONG):
+ printf("String is too long.\n");
+ continue;
case (PREPARE_SYNTAX_ERROR):
printf("Syntax error. Could not parse statement.\n");
continue;
然后这是测试:
+describe 'database' do
+ def run_script(commands)
+ raw_output = nil
+ IO.popen("./db", "r+") do |pipe|
+ commands.each do |command|
+ pipe.puts command
+ end
+
+ pipe.close_write
+
+ # Read entire output
+ raw_output = pipe.gets(nil)
+ end
+ raw_output.split("\n")
+ end
+
+ it 'inserts and retrieves a row' do
+ result = run_script([
+ "insert 1 user1 person1@example.com",
+ "select",
+ ".exit",
+ ])
+ expect(result).to match_array([
+ "db > Executed.",
+ "db > (1, user1, person1@example.com)",
+ "Executed.",
+ "db > ",
+ ])
+ end
+
+ it 'prints error message when table is full' do
+ script = (1..1401).map do |i|
+ "insert #{i} user#{i} person#{i}@example.com"
+ end
+ script << ".exit"
+ result = run_script(script)
+ expect(result[-2]).to eq('db > Error: Table full.')
+ end
+
+ it 'allows inserting strings that are the maximum length' do
+ long_username = "a"*32
+ long_email = "a"*255
+ script = [
+ "insert 1 #{long_username} #{long_email}",
+ "select",
+ ".exit",
+ ]
+ result = run_script(script)
+ expect(result).to match_array([
+ "db > Executed.",
+ "db > (1, #{long_username}, #{long_email})",
+ "Executed.",
+ "db > ",
+ ])
+ end
+
+ it 'prints error message if strings are too long' do
+ long_username = "a"*33
+ long_email = "a"*256
+ script = [
+ "insert 1 #{long_username} #{long_email}",
+ "select",
+ ".exit",
+ ]
+ result = run_script(script)
+ expect(result).to match_array([
+ "db > String is too long.",
+ "db > Executed.",
+ "db > ",
+ ])
+ end
+
+ it 'prints an error message if id is negative' do
+ script = [
+ "insert -1 cstack foo@bar.com",
+ "select",
+ ".exit",
+ ]
+ result = run_script(script)
+ expect(result).to match_array([
+ "db > ID must be positive.",
+ "db > Executed.",
+ "db > ",
+ ])
+ end
+end
Part 5 - Persistence to Disk
目前数据库允许插入记录并且读取,但仅限程序运行期间.如果关闭程序然后重新打开,所有的记录都消失了.我们期望的数据库表现应该是这样:
it 'keeps data after closing connection' do
result1 = run_script([
"insert 1 user1 person1@example.com",
".exit",
])
expect(result1).to match_array([
"db > Executed.",
"db > ",
])
result2 = run_script([
"select",
".exit",
])
expect(result2).to match_array([
"db > (1, user1, person1@example.com)",
"Executed.",
"db > ",
])
end
和sqlite一样,我们通过将整个数据库保存到文件中来永久存储记录.
我们目前已经可以将行序列化存储进页尺寸的内存块.为了实现永久存储,我们可以简单地把内存块写入文件,然后在下一次运行程序时把数据读取到内存中.
为了让事情更简单一点,我们将创建一个叫做pager的抽象层.我们向pager查询page X,然后pager返回一个内存块,pager首先在缓存中查找,如果缓存中没有这一页,就将数据从磁盘读取到内存(通过读取数据库文件).
SQLite架构具体到我们的数据库程序
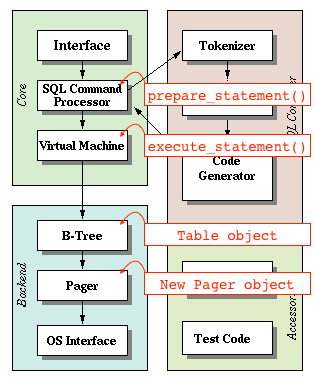
Pager负责page缓存和数据库文件,Table对象通过pager请求pages:
+typedef struct {
+ int file_descriptor;
+ uint32_t file_length;
+ void* pages[TABLE_MAX_PAGES];
+} Pager;
+
typedef struct {
- void* pages[TABLE_MAX_PAGES];
+ Pager* pager;
uint32_t num_rows;
} Table;
我将new_table()函数重命名为db_open()因为它现在负责打开数据库,开数据库,意味着:
- 打开数据库文件
- 初始化pager
- 初始化table
-Table* new_table() {
+Table* db_open(const char* filename) {
+ Pager* pager = pager_open(filename);
/*
译者注: 原文为 uint32_t num_rows = pager->file_length / ROW_SIZE;
但这里需要考虑page的大小不为row的整数倍的情况,所以不能直接用 文件大小/行大小 来求行数,
因为每页中可能还有一些空间是无效的(page只能放整数个row)
*/
+ uint32_t num_rows=pager->file_length/PAGE_SIZE*ROWS_PER_PAGE; //整页的所有行
+ uint32_t extra_bytes=pager->file_length%PAGE_SIZE;
+ if (extra_bytes>0){ //残缺页的额外行
+ uint32_t addtional_rows=extra_bytes/ROW_SIZE;
+ num_rows+=addtional_rows;
+ }
+
Table* table = malloc(sizeof(Table));
- table->num_rows = 0;
+ table->pager = pager;
+ table->num_rows = num_rows;
return table;
}
db_open()函数调用了pager_open(),pager_open打开一个数据库文件并追踪数据库大小.它还会将page缓存初始化为NULL.
+Pager* pager_open(const char* filename) {
+ int fd = open(filename,
+ O_RDWR | // Read/Write mode
+ O_CREAT, // Create file if it does not exist
+ S_IWUSR | // User write permission
+ S_IRUSR // User read permission
+ );
+
+ if (fd == -1) {
+ printf("Unable to open file\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t file_length = lseek(fd, 0, SEEK_END);
+
+ Pager* pager = malloc(sizeof(Pager));
+ pager->file_descriptor = fd;
+ pager->file_length = file_length;
+
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ pager->pages[i] = NULL;
+ }
+
+ return pager;
+}
因为有了新的pager层,所以我们把获取page的逻辑放入pager自己的方法中:
void* row_slot(Table* table, uint32_t row_num) {
uint32_t page_num = row_num / ROWS_PER_PAGE;
- void* page = table->pages[page_num];
- if (page == NULL) {
- // Allocate memory only when we try to access page
- page = table->pages[page_num] = malloc(PAGE_SIZE);
- }
+ void* page = get_page(table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
get_page()函数包含处理缓存未命中的逻辑.我们假设pages是一个接着一个的保存在数据库文件中的: Page 0 的偏移为0,Page 1 的偏移为4096(page大小为4096),page 2 的偏移为8192,etc.如果被请求的page超出了文件的边界,我们知道它应该是空白的,所以我们只需要分配一些内存空间然后返回它.稍后我们将缓存写入磁盘时page会被追加到文件中.
+void* get_page(Pager* pager, uint32_t page_num) {
+ if (page_num >= TABLE_MAX_PAGES) {
//译者注: 原文为 page_num > TABLE_MAX_PAGES,但page_num为下标,因此边界条件为TABLE_MAX_PAGES-1
+ printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
+ TABLE_MAX_PAGES);
+ exit(EXIT_FAILURE);
+ }
+
+ if (pager->pages[page_num] == NULL) {
+ // Cache miss. Allocate memory and load from file.
+ void* page = malloc(PAGE_SIZE);
+ uint32_t num_pages = pager->file_length / PAGE_SIZE;
+
+ // We might save a partial page at the end of the file
+ if (pager->file_length % PAGE_SIZE) {
+ num_pages += 1;
+ }
+
+ if (page_num <= num_pages-1) {
//译者注: 原文为 page_num<=num_pages 同样,因为page_num为下标而num_pages为页数,所以边界为num_pages-1
+ lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+ ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
+ if (bytes_read == -1) {
+ printf("Error reading file: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+ }
+
+ pager->pages[page_num] = page;
+ }
+
+ return pager->pages[page_num];
+}
目前来说,等到用户关闭数据库连接后,我们才把缓存写入磁盘.当用户退出时,我们调用一个新的函数db_close,它将
- 将页缓存写入磁盘
- 关闭数据库文件
- 释放Pager和Table的内存
+void db_close(Table* table) {
+ Pager* pager = table->pager;
+ uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
+
+ for (uint32_t i = 0; i < num_full_pages; i++) {
+ if (pager->pages[i] == NULL) {
+ continue;
+ }
+ pager_flush(pager, i, PAGE_SIZE);
+ free(pager->pages[i]);
+ pager->pages[i] = NULL;
+ }
+
+ // There may be a partial page to write to the end of the file
+ // This should not be needed after we switch to a B-tree
+ uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
+ if (num_additional_rows > 0) {
+ uint32_t page_num = num_full_pages;
+ if (pager->pages[page_num] != NULL) {
+ pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
+ free(pager->pages[page_num]);
+ pager->pages[page_num] = NULL;
+ }
+ }
+
+ int result = close(pager->file_descriptor);
+ if (result == -1) {
+ printf("Error closing db file.\n");
+ exit(EXIT_FAILURE);
+ }
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ void* page = pager->pages[i];
+ if (page) {
+ free(page);
+ pager->pages[i] = NULL;
+ }
+ }
+ free(pager);
+ free(table);
+}
+
-MetaCommandResult do_meta_command(InputBuffer* input_buffer) {
+MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
+ db_close(table);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
在我们目前的设计中,文件的长度取决于数据库中的行数,因此我们需要额外在末尾写入一页(如果行数不是rows_per_page的整数倍).这也是为什么pager_flush()函数有两个参数 - page下标和大小.这不是最好的设计,不过当我们实现B-tree的时候就不需要这个了.
+void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+ if (pager->pages[page_num] == NULL) {
+ printf("Tried to flush null page\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+
+ if (offset == -1) {
+ printf("Error seeking: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+
+ ssize_t bytes_written =
+ write(pager->file_descriptor, pager->pages[page_num], size);
+
+ if (bytes_written == -1) {
+ printf("Error writing: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+}
最后,我们需要接受命令行参数传递的文件名.不要忘了还要给do_meta_command函数加一个额外的参数.
int main(int argc, char* argv[]) {
- Table* table = new_table();
+ if (argc < 2) {
+ printf("Must supply a database filename.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ char* filename = argv[1];
+ Table* table = db_open(filename);
+
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (input_buffer->buffer[0] == '.') {
- switch (do_meta_command(input_buffer)) {
+ switch (do_meta_command(input_buffer, table)) {
做完这些修改,我们就可以关闭和重新打开数据库辣,并且我们的记录还在.
~ ./db mydb.db
db > insert 1 cstack foo@bar.com
Executed.
db > insert 2 voltorb volty@example.com
Executed.
db > .exit
~
~ ./db mydb.db
db > select
(1, cstack, foo@bar.com)
(2, voltorb, volty@example.com)
Executed.
db > .exit
~
For extra fun,让我们打开mydb.db看看数据是如何被存储的.我将会使用vim以16进制模式查看文件的内存布局:
文件格式
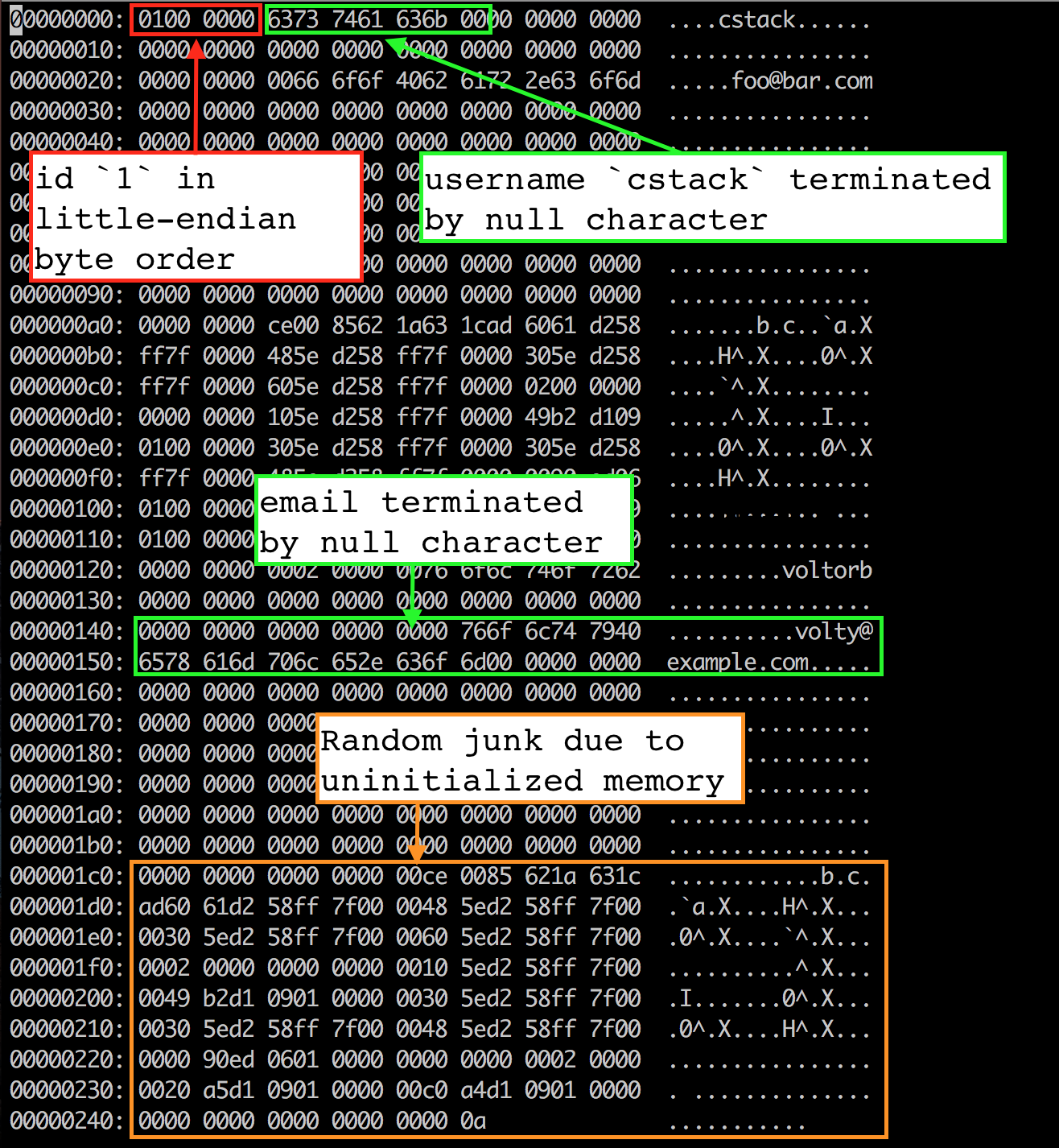
开头4个字节是第一行的id(4个字节因为id是uint32_t),它是以小端格式存储的,所以最低位字节为0x01,其他3为都为0x00.我们使用memcpy将Row结构体中的数据拷贝到page缓存,所以这也意味着内存中的结构体变量也是以小端序存储的.大端序还是小端序是由机器决定的(例如intel就是小端),如果我们在自己的机器上写入数据库文件,然后在另一个大端序的机器上读取,就需要完善serialize_row()和deserialize_row()函数,一直用同一种顺序存储和写入字节.
后面的33字节存储username字符串,以null字符为结尾.显然”cstack”的ASCII码的16进制格式为 63 73 74 61 63 6b,紧接着是一个null字符(0x00).剩余的33字节未被使用.
username后面的256字节用同样的方式存储email,在null字符之后可以看到一些随机的junk,这玩意的来源很可能是Row结构体未初始化的内存.我们将整整256字节的email缓存拷贝入文件,当把内存分配给结构体时,内存中的内容还在那儿.但是因为我们用了null字符标识字符串末尾,所以不会有什么影响.
注意: 如果我们想要确保所有字节都会被初始化,使用strncpy将username和email拷贝进内存(而不是memcpy)就可以,就像这样:
void serialize_row(Row* source, void* destination) {
memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
- memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
- memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+ strncpy(destination + USERNAME_OFFSET, source->username, USERNAME_SIZE);
+ strncpy(destination + EMAIL_OFFSET, source->email, EMAIL_SIZE);
}
注: 我想你们应该懒得查cpp ref,我帮你们查吧
大致意思就是,如果src(包括null字符)全都拷贝进了dest,还是没能达到
count个字节,那么dest剩余的部分都填充null字符,直到达到count.


Conclusion
好!我们已经完成了持久保存,但还有些地方可以改善.例如如果不用.exit而是直接终止程序,修改的数据就会丢失.此外,我们把所有的page都写回了磁盘,即使是从磁盘读取到内存后一直没改变的那些page,这些问题我们之后都可以解决.
下一章我们会介绍cursors,这会让实现B-tree更容易一些.
Until then!
Complete Diff
+#include <errno.h>
+#include <fcntl.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
+#include <unistd.h>
struct InputBuffer_t {
char* buffer;
@@ -62,9 +65,16 @@ const uint32_t PAGE_SIZE = 4096;
const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+typedef struct {
+ int file_descriptor;
+ uint32_t file_length;
+ void* pages[TABLE_MAX_PAGES];
+} Pager;
+
typedef struct {
uint32_t num_rows;
- void* pages[TABLE_MAX_PAGES];
+ Pager* pager;
} Table;
@@ -84,32 +94,81 @@ void deserialize_row(void *source, Row* destination) {
memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
}
+void* get_page(Pager* pager, uint32_t page_num) {
+ if (page_num > TABLE_MAX_PAGES) {
+ printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
+ TABLE_MAX_PAGES);
+ exit(EXIT_FAILURE);
+ }
+
+ if (pager->pages[page_num] == NULL) {
+ // Cache miss. Allocate memory and load from file.
+ void* page = malloc(PAGE_SIZE);
+ uint32_t num_pages = pager->file_length / PAGE_SIZE;
+
+ // We might save a partial page at the end of the file
+ if (pager->file_length % PAGE_SIZE) {
+ num_pages += 1;
+ }
+
+ if (page_num <= num_pages) {
+ lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+ ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
+ if (bytes_read == -1) {
+ printf("Error reading file: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+ }
+
+ pager->pages[page_num] = page;
+ }
+
+ return pager->pages[page_num];
+}
+
void* row_slot(Table* table, uint32_t row_num) {
uint32_t page_num = row_num / ROWS_PER_PAGE;
- void *page = table->pages[page_num];
- if (page == NULL) {
- // Allocate memory only when we try to access page
- page = table->pages[page_num] = malloc(PAGE_SIZE);
- }
+ void *page = get_page(table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
-Table* new_table() {
- Table* table = malloc(sizeof(Table));
- table->num_rows = 0;
+Pager* pager_open(const char* filename) {
+ int fd = open(filename,
+ O_RDWR | // Read/Write mode
+ O_CREAT, // Create file if it does not exist
+ S_IWUSR | // User write permission
+ S_IRUSR // User read permission
+ );
+
+ if (fd == -1) {
+ printf("Unable to open file\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t file_length = lseek(fd, 0, SEEK_END);
+
+ Pager* pager = malloc(sizeof(Pager));
+ pager->file_descriptor = fd;
+ pager->file_length = file_length;
+
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
- table->pages[i] = NULL;
+ pager->pages[i] = NULL;
}
- return table;
+
+ return pager;
}
-void free_table(Table* table) {
- for (int i = 0; table->pages[i]; i++) {
- free(table->pages[i]);
- }
- free(table);
+Table* db_open(const char* filename) {
+ Pager* pager = pager_open(filename);
+ uint32_t num_rows = pager->file_length / ROW_SIZE;
+
+ Table* table = malloc(sizeof(Table));
+ table->pager = pager;
+ table->num_rows = num_rows;
+
+ return table;
}
InputBuffer* new_input_buffer() {
@@ -142,10 +201,76 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
+void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+ if (pager->pages[page_num] == NULL) {
+ printf("Tried to flush null page\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE,
+ SEEK_SET);
+
+ if (offset == -1) {
+ printf("Error seeking: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+
+ ssize_t bytes_written = write(
+ pager->file_descriptor, pager->pages[page_num], size
+ );
+
+ if (bytes_written == -1) {
+ printf("Error writing: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+}
+
+void db_close(Table* table) {
+ Pager* pager = table->pager;
+ uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
+
+ for (uint32_t i = 0; i < num_full_pages; i++) {
+ if (pager->pages[i] == NULL) {
+ continue;
+ }
+ pager_flush(pager, i, PAGE_SIZE);
+ free(pager->pages[i]);
+ pager->pages[i] = NULL;
+ }
+
+ // There may be a partial page to write to the end of the file
+ // This should not be needed after we switch to a B-tree
+ uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
+ if (num_additional_rows > 0) {
+ uint32_t page_num = num_full_pages;
+ if (pager->pages[page_num] != NULL) {
+ pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
+ free(pager->pages[page_num]);
+ pager->pages[page_num] = NULL;
+ }
+ }
+
+ int result = close(pager->file_descriptor);
+ if (result == -1) {
+ printf("Error closing db file.\n");
+ exit(EXIT_FAILURE);
+ }
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ void* page = pager->pages[i];
+ if (page) {
+ free(page);
+ pager->pages[i] = NULL;
+ }
+ }
+
+ free(pager);
+ free(table);
+}
+
MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
- free_table(table);
+ db_close(table);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
@@ -182,6 +308,7 @@ PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) {
return PREPARE_SUCCESS;
}
+
PrepareResult prepare_statement(InputBuffer* input_buffer,
Statement* statement) {
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
@@ -227,7 +354,14 @@ ExecuteResult execute_statement(Statement* statement, Table *table) {
}
int main(int argc, char* argv[]) {
- Table* table = new_table();
+ if (argc < 2) {
+ printf("Must supply a database filename.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ char* filename = argv[1];
+ Table* table = db_open(filename);
+
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
然后这是测试部分的改动:
呃..原作者有点不太细心
实际上自从part4把email和username的大小都加了1字节后,最大存储的行数为1300
4096/(4+33+256=293)=13.9 也就是每页只能存储13行,最多100页
And the diff to our tests:
describe 'database' do
+ before do
+ `rm -rf test.db`
+ end
+
def run_script(commands)
raw_output = nil
- IO.popen("./db", "r+") do |pipe|
+ IO.popen("./db test.db", "r+") do |pipe|
commands.each do |command|
pipe.puts command
end
@@ -28,6 +32,27 @@ describe 'database' do
])
end
+ it 'keeps data after closing connection' do
+ result1 = run_script([
+ "insert 1 user1 person1@example.com",
+ ".exit",
+ ])
+ expect(result1).to match_array([
+ "db > Executed.",
+ "db > ",
+ ])
+
+ result2 = run_script([
+ "select",
+ ".exit",
+ ])
+ expect(result2).to match_array([
+ "db > (1, user1, person1@example.com)",
+ "Executed.",
+ "db > ",
+ ])
+ end
+
it 'prints error message when table is full' do
script = (1..1401).map do |i|
"insert #{i} user#{i} person#{i}@example.com"
Part 6 - The Cursor Abstraction
这一章应该比上一章短一点.我们只需要重构一点点代码,以此来让实现B-Tree更容易一点.
我们需要添加一个表示Cursor对象,它用来表示在table中的位置.
你可能想用cursors做的事:
- 在table的开头创建一个cursor
- 在table的末尾创建一个cursor
- 获取cursor指向的row
- 将cursor移动到下一行
这些是我们将要实施的行为.稍后,我们还会:
- 删除cursor指向的row
- 修改cursor指向的row
- 用给定的ID在table中搜索,然后用该ID创建一个指向那一行的cursor
先说这么多,这里是Cursor的定义:
+typedef struct {
+ Table* table;
+ uint32_t row_num;
+ bool end_of_table; // Indicates a position one past the last element
+} Cursor;
基于我们目前的table结构体,table中的位置可以用row number标识.
cursor还具有对其所归属的table的引用(所以我们的cursor函数只需要cursor一个参数).
最后,它还有一个布尔变量end_of_table,这被用来表示table的末尾的后一个位置(也就是我们想要插入新一行的位置).
函数table_start()和table_end()创建新的cursors:
+Cursor* table_start(Table* table) {
+ Cursor* cursor = malloc(sizeof(Cursor));
+ cursor->table = table;
+ cursor->row_num = 0;
+ cursor->end_of_table = (table->num_rows == 0);
+
+ return cursor;
+}
+
+Cursor* table_end(Table* table) {
+ Cursor* cursor = malloc(sizeof(Cursor));
+ cursor->table = table;
+ cursor->row_num = table->num_rows;
+ cursor->end_of_table = true;
+
+ return cursor;
+}
函数row_slot()会变成cursor_value(),该函数会通过cursor描述的位置返回一个指向该行位置的指针:
-void* row_slot(Table* table, uint32_t row_num) {
+void* cursor_value(Cursor* cursor) {
+ uint32_t row_num = cursor->row_num;
uint32_t page_num = row_num / ROWS_PER_PAGE;
- void* page = get_page(table->pager, page_num);
+ void* page = get_page(cursor->table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
基于目前的table结构体,将cursor移动到下一行和增加行号一样简单,而在B-tree中会稍复杂一些.
+void cursor_advance(Cursor* cursor) {
+ cursor->row_num += 1;
+ if (cursor->row_num >= cursor->table->num_rows) {
+ cursor->end_of_table = true;
+ }
+}
最后我们需要让”虚拟机”的函数使用cursor这一抽象数据结构.当我们插入一行事,我们打开一个指向table末尾的cursor,数据写入到cursor对应的位置,然后释放cursor.
Row* row_to_insert = &(statement->row_to_insert);
+ Cursor* cursor = table_end(table);
- serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ serialize_row(row_to_insert, cursor_value(cursor));
table->num_rows += 1;
+ free(cursor);
+
return EXECUTE_SUCCESS;
}
当选中table的所有行,我们打开一个指向table开头的cursor,打印这一行,然后cursor移动到下一行.一直重复到到达table的末尾.
ExecuteResult execute_select(Statement* statement, Table* table) {
+ Cursor* cursor = table_start(table);
+
Row row;
- for (uint32_t i = 0; i < table->num_rows; i++) {
- deserialize_row(row_slot(table, i), &row);
+ while (!(cursor->end_of_table)) {
+ deserialize_row(cursor_value(cursor), &row);
print_row(&row);
+ cursor_advance(cursor);
}
+
+ free(cursor);
+
return EXECUTE_SUCCESS;
}
好了,做完辣!和我说的一样,这个小小的重构在我们将table结构体重写成B-tree的时候提供帮助.
函数execute_select()和execute_insert()可以通过cursor和table完整的交互,而不需要在乎table是如何存储的.
这里是本章的全部改动:
@@ -78,6 +78,13 @@ struct {
} Table;
+typedef struct {
+ Table* table;
+ uint32_t row_num;
+ bool end_of_table; // Indicates a position one past the last element
+} Cursor;
+
void print_row(Row* row) {
printf("(%d, %s, %s)\n", row->id, row->username, row->email);
}
@@ -126,12 +133,38 @@ void* get_page(Pager* pager, uint32_t page_num) {
return pager->pages[page_num];
}
-void* row_slot(Table* table, uint32_t row_num) {
- uint32_t page_num = row_num / ROWS_PER_PAGE;
- void *page = get_page(table->pager, page_num);
- uint32_t row_offset = row_num % ROWS_PER_PAGE;
- uint32_t byte_offset = row_offset * ROW_SIZE;
- return page + byte_offset;
+Cursor* table_start(Table* table) {
+ Cursor* cursor = malloc(sizeof(Cursor));
+ cursor->table = table;
+ cursor->row_num = 0;
+ cursor->end_of_table = (table->num_rows == 0);
+
+ return cursor;
+}
+
+Cursor* table_end(Table* table) {
+ Cursor* cursor = malloc(sizeof(Cursor));
+ cursor->table = table;
+ cursor->row_num = table->num_rows;
+ cursor->end_of_table = true;
+
+ return cursor;
+}
+
+void* cursor_value(Cursor* cursor) {
+ uint32_t row_num = cursor->row_num;
+ uint32_t page_num = row_num / ROWS_PER_PAGE;
+ void *page = get_page(cursor->table->pager, page_num);
+ uint32_t row_offset = row_num % ROWS_PER_PAGE;
+ uint32_t byte_offset = row_offset * ROW_SIZE;
+ return page + byte_offset;
+}
+
+void cursor_advance(Cursor* cursor) {
+ cursor->row_num += 1;
+ if (cursor->row_num >= cursor->table->num_rows) {
+ cursor->end_of_table = true;
+ }
}
Pager* pager_open(const char* filename) {
@@ -327,19 +360,28 @@ ExecuteResult execute_insert(Statement* statement, Table* table) {
}
Row* row_to_insert = &(statement->row_to_insert);
+ Cursor* cursor = table_end(table);
- serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ serialize_row(row_to_insert, cursor_value(cursor));
table->num_rows += 1;
+ free(cursor);
+
return EXECUTE_SUCCESS;
}
ExecuteResult execute_select(Statement* statement, Table* table) {
+ Cursor* cursor = table_start(table);
+
Row row;
- for (uint32_t i = 0; i < table->num_rows; i++) {
- deserialize_row(row_slot(table, i), &row);
+ while (!(cursor->end_of_table)) {
+ deserialize_row(cursor_value(cursor), &row);
print_row(&row);
+ cursor_advance(cursor);
}
+
+ free(cursor);
+
return EXECUTE_SUCCESS;
}
Part 7 - Introduction to the B-Tree
B-Tree是SqLite用来表示tabls和索引的数据结构,所以它是一个很核心的概念.本章只会介绍这种数据结构,不会包含任何代码.
为森莫树这种数据结构非常适合数据库捏?
- 搜索数据的速度非常快(O(logn)时间复杂度)
- 插入/删除你找到的值非常快(平衡操作时间复杂度为O(1))
- 遍历范围内的数值很快(而不像hash map)
B-Tree和二叉树不同(“B”可能是来自发明者的名字,但也可能表示”平衡”).这里有一个B-Tree的例子:
example B-Tree (https://en.wikipedia.org/wiki/File:B-tree.svg)
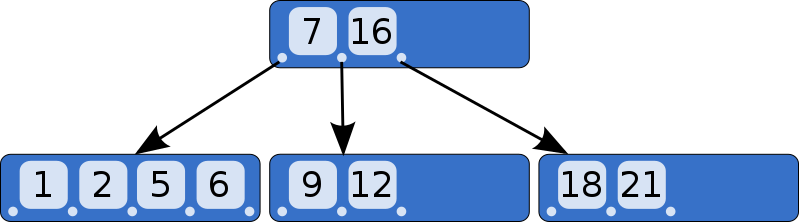
与二叉树不同,B-Tree的每一个节点可以有两个以上的孩子.每个节点至多拥有m个孩子,m叫做树的”阶”.为了保持树尽可能平衡,节点至少得拥有m/2(四舍五入)个孩子.
特殊情况:
- 叶子节点没有孩子
- 根节点的孩子可以少于
m个但至少得是2个 - 如果根节点是叶子节点(树只有一个节点),那么它有0个孩子
上面的图片是一棵B-Tree,SQLite用它来存储索引.至于存储tables,Sqlite使用B-Tree的变种-B+ Tree.
| B-Tree | B+ Tree | |
|---|---|---|
| 发音 | "Bee Tree" | "Bee Plus Tree" |
| 存储的数据 | 索引 Index | 表格 Table |
| 内部节点存储key | yes | yes |
| 内部节点存储value | yes | no |
| 每个节点的子节点 | Less | More |
| 内部节点 vs 叶子节点 | 结构相同 | 结构不同 |
在我们实现index之前,我只会介绍B+Tree,但我会把它称为 B-Tree或者btree.
有孩子的节点叫做”内部”节点,内部节点和叶子节点具有不同的结构:
| 一棵m阶树… | 内部节点 | 叶子节点 |
|---|---|---|
| 存储 | key & 指向孩子的指针 | key & value |
| key的个数 | 至多 m-1 | 尽可能多 |
| 指针的个数 | key的个数+1 | none |
| value的个数 | none | 和key的个数一样 |
| key的作用 | 用于路由 | 和value配对 |
| 存储value? | no | yes |
让我们通过一个例子来看一棵B-tree在插入元素后是如何成长的,简单起见,tree是三阶的,这意味着:
- 内部节点至多有3个孩子
- 内部节点至多有2个key
- 内部节点至少有2个孩子
- 内部节点至少有1个key
一棵空B-tree只有一个节点:根节点.
根节点一开始是一个没有键值对的叶子节点:
empty btree
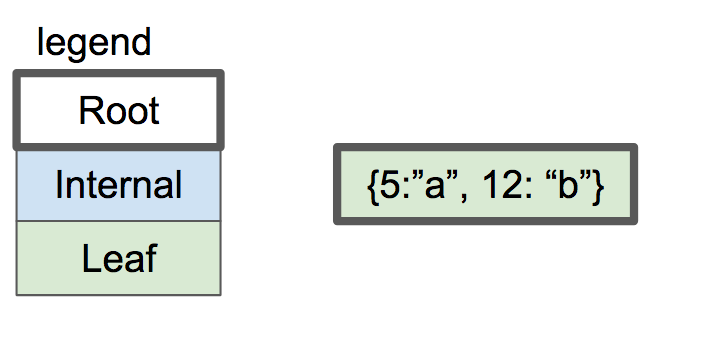
如果我们插入了2个键值对,他们会按顺序被存储在叶子节点.
on-node btree
让我们规定叶子节点的容量为2个键值对.当我们插入另一个,我们得分裂叶子节点然后叶子节点平分键值对.每个叶子节点都会成为一个新的内部节点的孩子(该内部节点现在变成了根节点.)
two-level btree
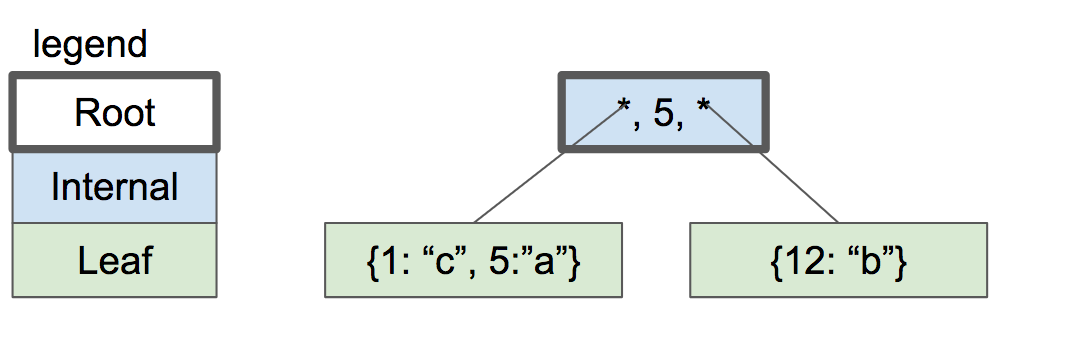
内部节点现在拥有1个key和2个指向孩子的指针.如果我们想要查找一个<=5的key,我们会在左孩子里查找,如果想找>=5的key,会在右孩子里查找.
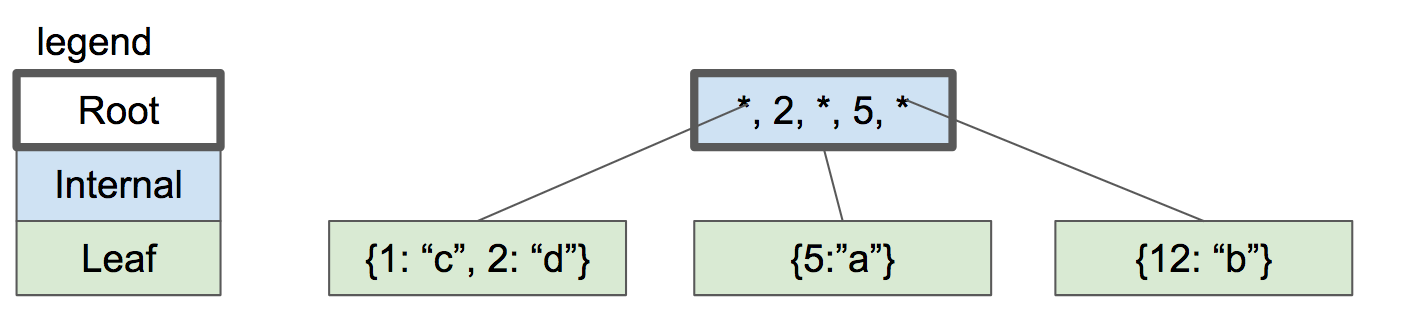
现在让我们插入key “2”.首先我们会查找它可能在里面的叶子节点,然后我们到达了左边的叶子节点.这个节点满了,所以我们分裂它然后在父节点中创建一个新的入口.
four-node btree
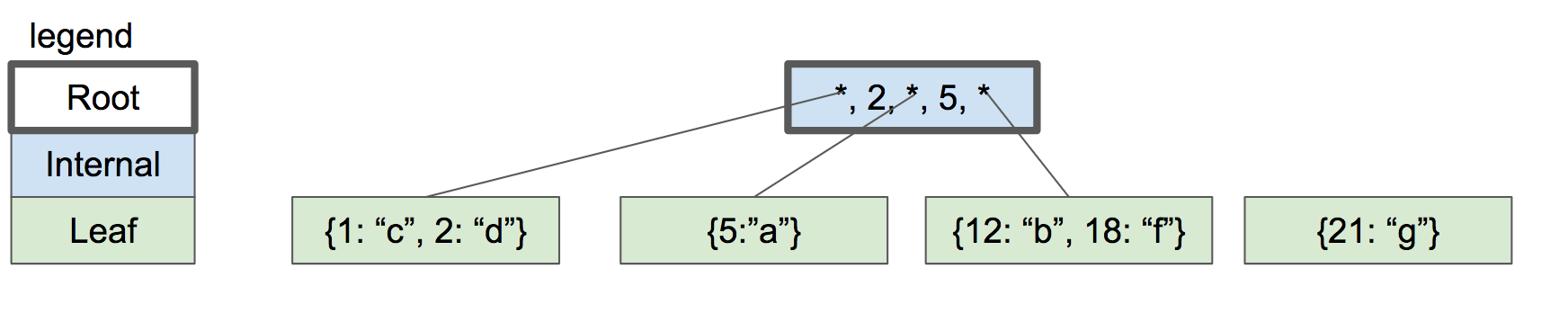
让我们继续增加key 18&21,我们不得不再次分裂节点.但是父节点中没有空间存放另一个键值对了(key个数最多为m-1=2).
no room in internal node
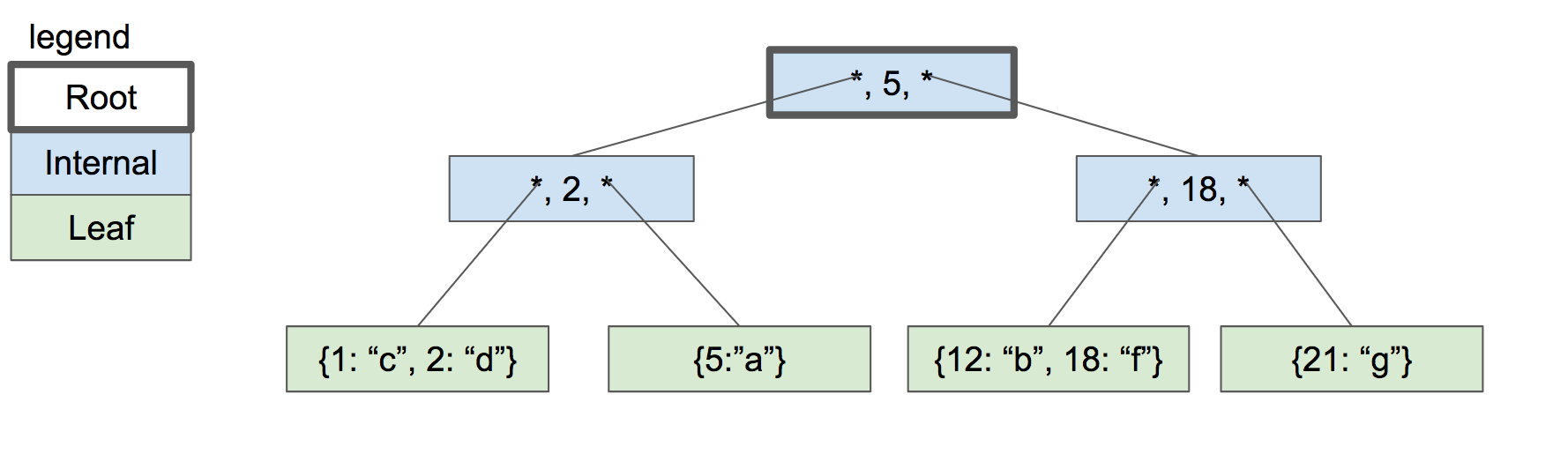
解决方案是分裂根节点为两个内部节点,然后创建一个新的根节点作为它们的父节点.
three-level btree
树的高度只有在我们分裂根节点的时候增加.每个叶子节点都有相同的深度和数量大致相同的键值对,所以树保持了平衡然后可以快速搜索.
我暂且不会讨论删除tree的key直到我们实施了插入操作.
当我们实施了这一数据结构,每个节点会对应一个page.根节点会在page 0,指向孩子的指针实际上是该孩子节点的page number.
下一次,我们开始实施 btree!
鉴于全部章节内容实在是有、小多,所以第7章后面的放在了另一个地方